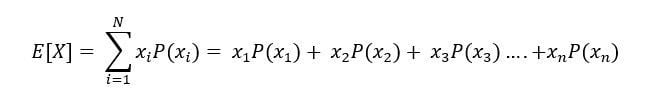Walpole Myers Myers Ye
Esperanza Matematica
Pag. 113
Ejemplo 1

Ejemplo 2

Ejemplo 3

Ejemplo 4

Pagina 150-151



 La gráfica de su función de densidad tiene una forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva se conoce como campana de Gauss y es el gráfico de una función gaussiana.
La gráfica de su función de densidad tiene una forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva se conoce como campana de Gauss y es el gráfico de una función gaussiana. -errores cometidos al medir ciertas magnitudes;
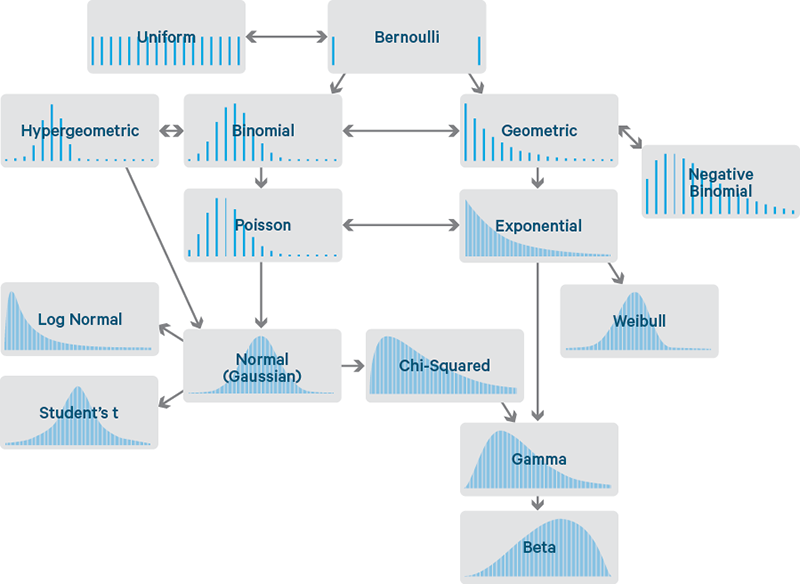
-errores cometidos al medir ciertas magnitudes; En estadística, la distribución binomial es una distribución de probabilidad discreta que cuenta el número de éxitos en una secuencia de n ensayos de Bernoulli independientes entre sí, con una probabilidad fija p de ocurrencia del éxito entre los ensayos. Un experimento de Bernoulli se caracteriza por ser dicotómico, esto es, solo dos resultados son posibles. A uno de estos se denomina «éxito» y tiene una probabilidad de ocurrencia p y al otro, «fracaso», con una probabilidad2 q = 1 - p. En la distribución binomial el anterior experimento se repite n veces, de forma independiente, y se trata de calcular la probabilidad de un determinado número de éxitos. Para n = 1, la binomial se convierte, de hecho, en una distribución de Bernoulli.
En estadística, la distribución binomial es una distribución de probabilidad discreta que cuenta el número de éxitos en una secuencia de n ensayos de Bernoulli independientes entre sí, con una probabilidad fija p de ocurrencia del éxito entre los ensayos. Un experimento de Bernoulli se caracteriza por ser dicotómico, esto es, solo dos resultados son posibles. A uno de estos se denomina «éxito» y tiene una probabilidad de ocurrencia p y al otro, «fracaso», con una probabilidad2 q = 1 - p. En la distribución binomial el anterior experimento se repite n veces, de forma independiente, y se trata de calcular la probabilidad de un determinado número de éxitos. Para n = 1, la binomial se convierte, de hecho, en una distribución de Bernoulli.
 La distribución hipergeométrica es una distribución discreta que modela el número de eventos en una muestra de tamaño fijo cuando usted conoce el número total de elementos en la población de la cual proviene la muestra. Cada elemento de la muestra tiene dos resultados posibles (es un evento o un no evento). Las muestras no tienen reemplazo, por lo que cada elemento de la muestra es diferente. Cuando se elige un elemento de la población, no se puede volver a elegir. Por lo tanto, la probabilidad de que un elemento sea seleccionado aumenta con cada ensayo, presuponiendo que aún no haya sido seleccionado.
La distribución hipergeométrica es una distribución discreta que modela el número de eventos en una muestra de tamaño fijo cuando usted conoce el número total de elementos en la población de la cual proviene la muestra. Cada elemento de la muestra tiene dos resultados posibles (es un evento o un no evento). Las muestras no tienen reemplazo, por lo que cada elemento de la muestra es diferente. Cuando se elige un elemento de la población, no se puede volver a elegir. Por lo tanto, la probabilidad de que un elemento sea seleccionado aumenta con cada ensayo, presuponiendo que aún no haya sido seleccionado.|
DISTRIBUCION BINOMIAL |
DISTRIBUCIÓN HIPERGEOMÉTRICA |
|
·
En los experimentos que tienen este tipo de distribución, siempre
se esperan dos tipos de resultados, ejem. Defectuoso, no defectuoso, pasa, no
pasa, etc, etc., denominados arbitrariamente “éxito” (que es lo que se espera
que ocurra) o “fracaso” (lo contrario del éxito). ·
Las probabilidades asociadas a cada uno de estos resultados son
constantes, es decir no cambian. ·
Cada uno de los ensayos o repeticiones del experimento son
independientes entre sí. ·
El número de ensayos o repeticiones del experimento (n) es
constante. |
·
Al realizar un experimento con este tipo de distribución, se
esperan dos tipos de resultados. ·
Las probabilidades asociadas a cada uno de los resultados no son
constantes. ·
Cada ensayo o repetición del experimento no es independiente de
los demás. ·
El número de repeticiones del experimento (n) es constante. |

| x | P (X = x) |
|---|---|
| 5 | 0.037833 |
| 10 | 0.12511 |
| 15 | 0.034718 |
Gráfica de distribución del número de quejas de clientes
 La esperanza matemática, también llamada valor esperado, es igual al sumatorio de las probabilidades de que exista un suceso aleatorio, multiplicado por el valor del suceso aleatorio. O, dicho de otra forma, el valor medio de un conjunto de datos. Teniendo en cuenta, eso sí, que el término esperanza matemática está acuñado por la teoría de la probabilidad. Mientras que en matemáticas, se denomina media matemática al valor promedio de un suceso que ha ocurrido. En distribuciones discretas con la misma probabilidad en cada suceso la media aritmética es igual que la esperanza matemática.
La esperanza matemática, también llamada valor esperado, es igual al sumatorio de las probabilidades de que exista un suceso aleatorio, multiplicado por el valor del suceso aleatorio. O, dicho de otra forma, el valor medio de un conjunto de datos. Teniendo en cuenta, eso sí, que el término esperanza matemática está acuñado por la teoría de la probabilidad. Mientras que en matemáticas, se denomina media matemática al valor promedio de un suceso que ha ocurrido. En distribuciones discretas con la misma probabilidad en cada suceso la media aritmética es igual que la esperanza matemática.